S3 Multi-region Access Point

Former Airline Pilot switching to a career in the Cloud + Project Management.
Let's say that your company, undergoing cloud migration, had to store terabytes of its critical data in multiple regions for disaster recovery reasons and as well as for compliance with regulations. It would be simple if the data was unchanging and was available right when it needs to be migrated to the cloud. Just upload it to different S3 buckets in different regions and set its storage class to Glacier.
However, this wouldn't be the case since with a migration, most likely, that transfer will be done in batches and depending on the situation, more data would be added onto that daily. Imagine how tedious it would be to manually make sure that all data copied into multiple S3 buckets are in sync
This is a scenario where MRAP will come in handy since it will allow you to synchronize the access and data stored in S3 buckets located in different regions through a single global endpoint. MRAP simplifies the management of data in this scenario and helps with resilience and compliance with applicable regulations.
Additionally, in a more general sense, MRAP lowers the latency if users of the data/application are scattered around multiple regions globally. To note, depending on the use case, CloudFront is also a suitable solution for delivering content to users around the world.
In the following mini-project, let's explore how to create MRAP for two S3 buckets in different regions and see how data moves to and between. Sample data is created and uploaded to the MRAP and the replication of that file is observed.
This is part of Adrian Cantrill's SAA C03 course. -website -Github
Step by step
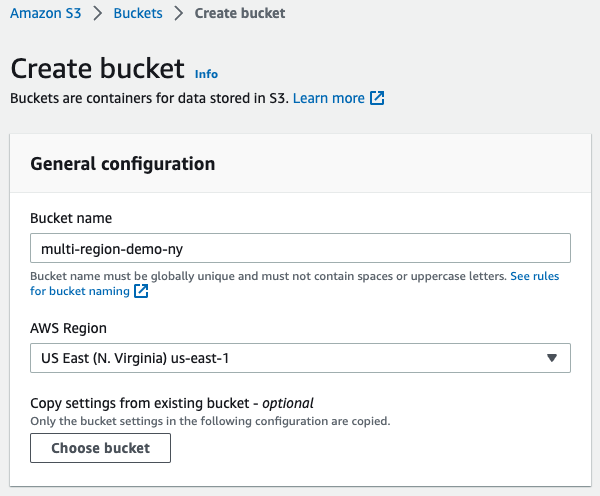
1.) Create the first bucket
Ideally, create the first bucket in your home region, then create the next bucket in a faraway region.
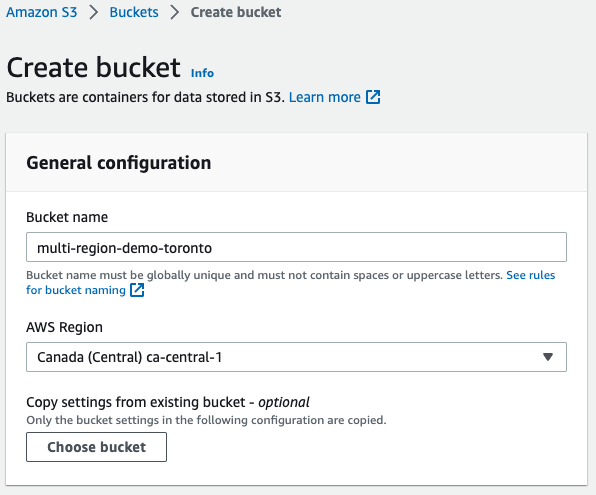
2.) Create the second bucket
I created the bucket with Toronto in the name since I assumed that it was where Canada (Central) is. It is actually in Montreal and like I mentioned above, a farther region should have been chosen to follow the tests made in the mini-project
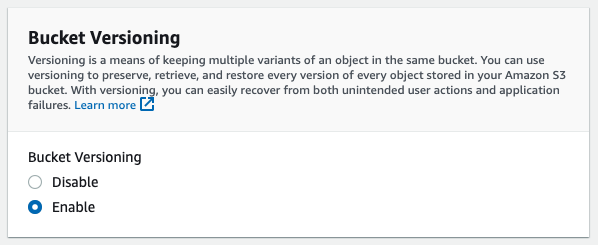
Remember to enable versioning in this bucket as well.
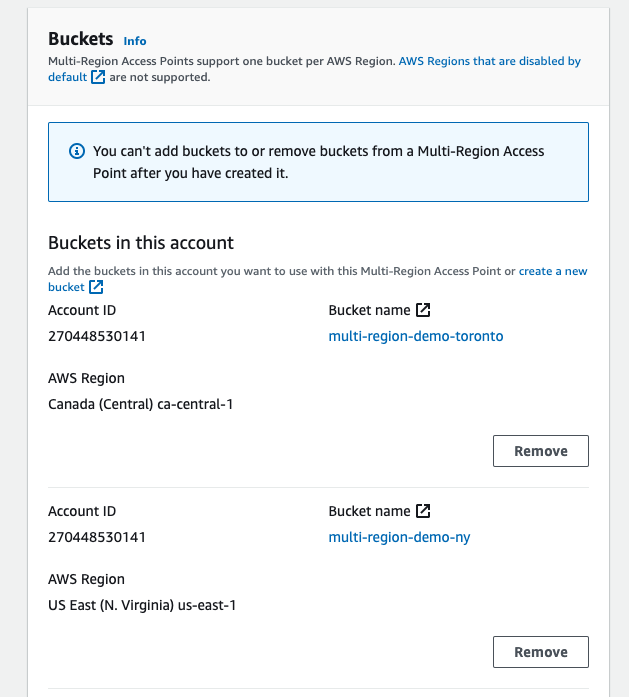
3.) Multi-region Access Point Creation
Select the Multi-region Access Points on the left pane.
Create the MRAP and select both buckets.
4.) Waiting time

Could take 30 minutes to 24 hours with mine taking around 30 minutes to create.
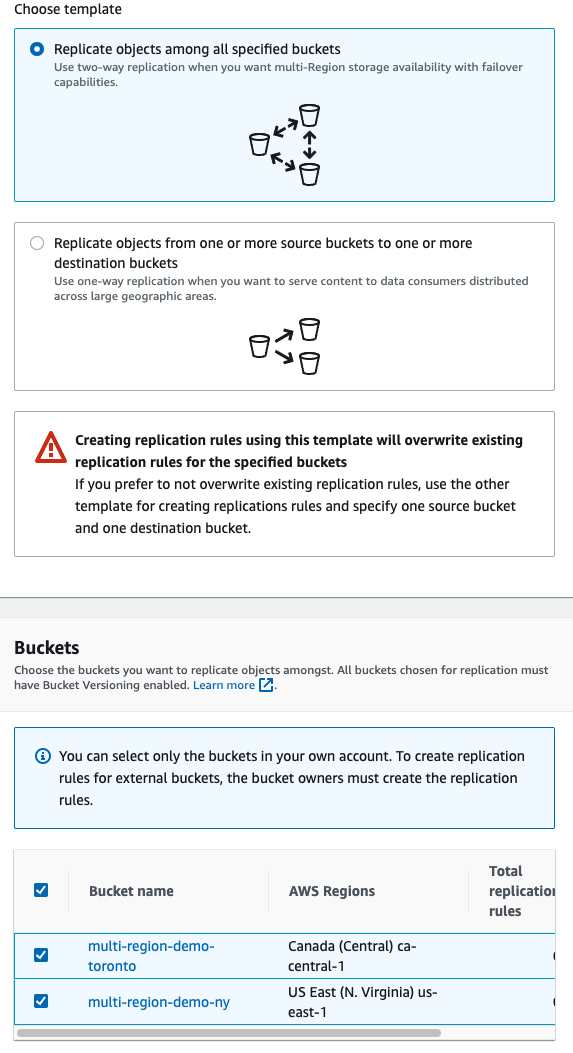
5.) Configure replication between two buckets
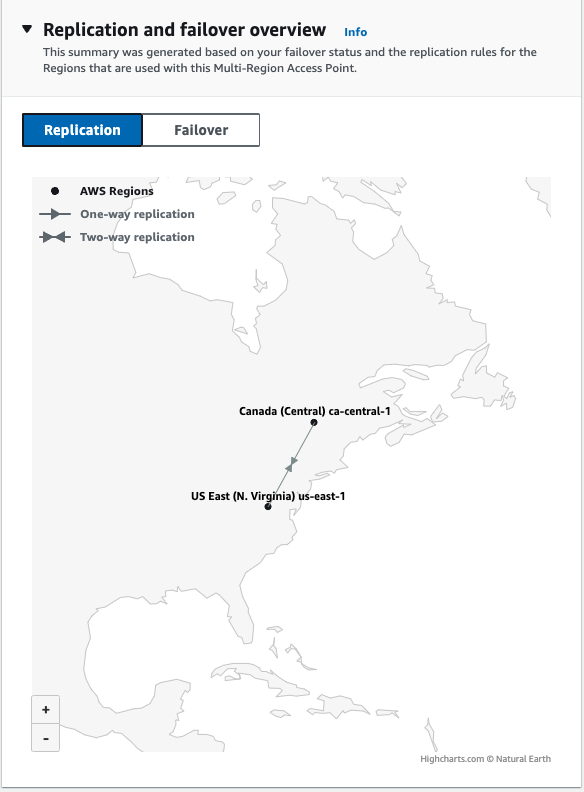
Anyone accessing buckets will be directed to nearest bucket.
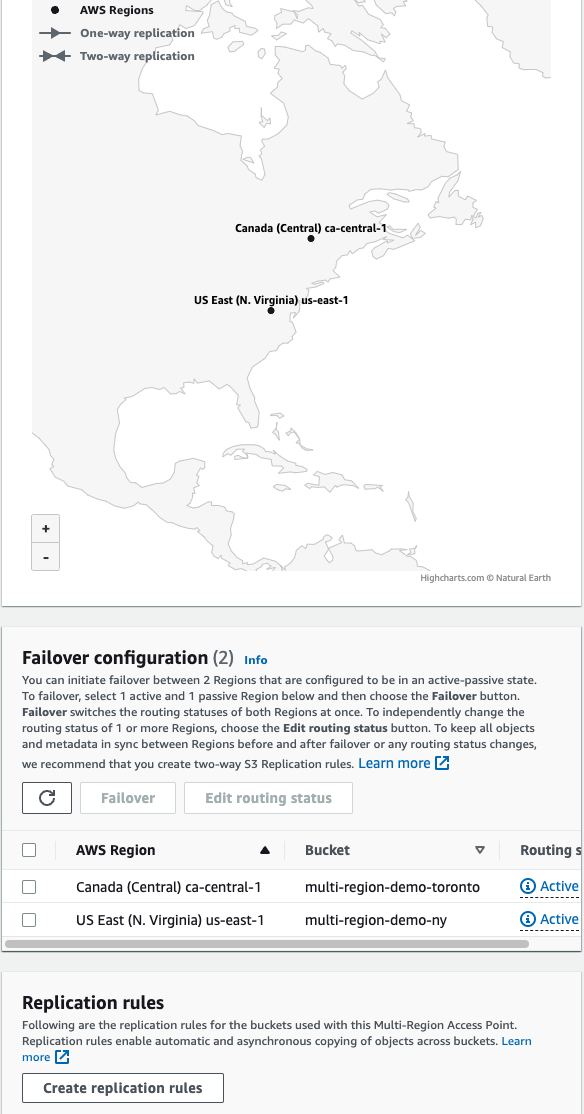
Both being in Active Failover configuration means that any request made to AP will be delivered to either of these s3 buckets as long as they are available. One being passive means it will only be used if no active buckets exist.
6.) Test out multi-region access point using Cloudshell
Move to a different region other than the two buckets were created in but in one that supports Cloudshell.
Initially tried California but was notified through a prompt that Cloudshell is not available in that region. Thus I chose US West 2 (Ohio).
Enter the following commands for the creation of the data onto the shell and for the upload onto the MRAP.
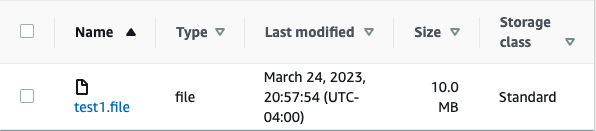
dd if=/dev/urandom of=test1.file bs=1M count=10
#creates a 10MB file random data with name test1.file

Get the ARN for the bucket by going to S3 in the console.
aws s3 cp test1.file s3://arn:aws:s3::270448530141:accesspoint/myn8hqdttfijb.mrap
# copy created file to multi region access point.
MRAP will direct to the closest S3 bucket it serves. In my case, the closest S3 bucket was US East 1.

7.) Try the above in a different region.
The bucket should be closer to the second bucket that was uploaded to by MRAP but not in the same region. I chose EU WEST 2 (London). Since my two original buckets are relatively close to each other, I had to pick one that seemed closer to the second region but still, it is quite a distance to both.
dd if=/dev/urandom of=test2.file bs=1M count=10
#creates a 10MB file random data with name test2.file

aws s3 cp test2.file s3://arn:aws:s3::270448530141:accesspoint/myn8hqdttfijb.mrap
# copy created file to multi region access point.
The file was still uploaded to US East 1 (N. Virginia) before Canada (Central). An online search would yield that the Canada Central location is actually closer by 1000km from EU WEST 2 (London). I would assume that latency may have something to do with the MRAP choosing N. Virginia. The file arrived in the Canada bucket at about 14 minutes after the first upload.
Try the above steps again (name the file: test3.file) at another region somewhere in between both regions. Since my two buckets don't have a region that's in between them, I just picked the farthest one from both. I chose to test AP-southeast-2 (Sydney) and the file was still uploaded to N. Virginia. The file was replicated around 30 minutes after upload.
8.) Consistency lag
As the last step, open two terminals in the regions of the two buckets and in one region, upload the file onto MRAP like the above. In the second region, type the following:
aws s3 cp s3://arn:aws:s3::270448530141:accesspoint/myn8hqdttfijb.mrap .
#copies the test4.file from the MRAP into the Cloudshell in the region.
The code attempts to copy that file created in the first region into the Cloudshell but it was not successful at first. This is one downside of the MRAP but can be mitigated by using the RTC (Replication Time Control) option which replicates the files within 15 minutes of upload.
Overall
The steps above shows the creation of two buckets in different regions and the usage of MRAP to duplicate data in the buckets. As shown, there is a delay in the replication of data. Depending on the business scenario and company or compliance requirements, that delay may be acceptable. An RTC could be set to try replicating data within a specified timeframe but is not always guaranteed.
Part of cover photo image made by screenshot from AWS.




